今回は神奈川県藤沢市辻堂西海岸にある「コメダ珈琲店 なぎさモール辻堂店」にてランチ&ノマドです。

店舗前に到着。最寄りはJR辻堂駅ですが徒歩20~30分はかかります。辻堂海岸の方が近い。

ミックストーストを注文しました。具が大量で美味い。その後、コメダのフリーWIFIにて少しPC作業しました。よくあるコメダという感じ。
BlenderのレンダリングがオンラインのPython実行環境であるGoogle Colaboratoryでもできると聞いて試してみました(Colabだと無料GPUが使えるので人によっては速くなるかも)。
「Blender Colab」でググって一番始めにヒットしたこちらのColabノートブックを使ってみます。しかし、GPUを有効にしてレンダリングしてみるとエラーが出て失敗(「Failed to create CUDA context unknown error」やら)(本記事の公開時から更新されている可能性もあるので注意)。
調べてみるとほぼピンポイントに解説してくれている以下の動画を発見。これ見れば多分大丈夫ですが一応この記事でも解説しておきます。
Colab無料版でほぼ毎回割り当てられる「Tesla K80」がOptiXによるレンダリングに対応してないらしいので、コマンドオプションで「-- --cycles-device OPTIX」となっている場合は「-- --cycles-device CUDA」に変更します(上記Colabノートブックでは「!sudo ./$blender_version/blender -b 'render/{blend_file_path}' -P setgpu.py -E CYCLES -o '{output_path}' -noaudio ...」の辺り)。
※Cycles固有のオプションは「--」で記述するらしい。
恐らくまだエラー出るので更に同コマンドの頭にあるsudoを消します(Colabはデフォルトでrootユーザーだから?)。
まだ動きません。「libtcmalloc-minimal4」というパッケージのバージョンが違うらしいのでインストールし直すコードを前に挿入します(以下URLよりコピペさせてもらうと楽)。

以上を修正して再度実行、GPUでレンダリングできました(写真)!ちなみにこれは床井先生のCG制作演習資料を見て作った雪だるまにテキストを付けたやつです。
他に書いた記事。
※こちらは創作+機械学習 Advent Calendar 2021 10日目の記事です。
まずは以下の画像をご覧ください。

こちらの方が誰かご存知でしょうか?
なんとこの人は現実には存在しないAIが生成した画像なんです(というGANでよく聞く謳い文句)。機械学習、特に中でもDeep Learningの技術が発展しAIによって実在の人物と見分けがつかないレベルの高品質な画像もここ数年で生成できるようになりました。
※ちなみに上の画像はこちらのWeb上で動かせるデモで生成しました。
せっかくなので以下の動画もご覧ください。
これは先ほど載せた顔画像を生成したAIモデルと同じものを使って作られた映像です。モデルへの入力となる変数を少しずつ変えることで生成される画像も少しずつ変わるという特徴を活かし、それらの画像をつなげることでこのようなモーフィング映像ができあがります(超ざっくりな説明です)。
気持ち悪いと思われるかもしれませんがAIはそんなこと思っていないかも?しれません(私が意図的に変な出力にしました)。
AIというと実用的な面ばかりが注目されがちですが、同じAIの技術を使ってアートな作品を制作している人たちもいます。本記事では数多くあるAI技術の中から冒頭でも載せたGANの解説と作品制作に役立ちそうな情報をざっくりご紹介しようと思います。

まずGANとはGenerative Adversarial Network(敵対的生成ネットワーク)の略であり、機械学習の技術の中でも生成モデルといわれる中の1つです。大量のデータを学習させることでどこかしら似てはいるけど実在しない画像を生成したりできます(画像のイメージが強いですが音楽など違うものを生成する事例もあります)。
「敵対的生成ネットワーク - Wikipedia」の説明も一部引用します。
GANsは生成ネットワーク(generator)と識別ネットワーク(discriminator)の2つのネットワークから構成される。例として画像生成を目的とするなら生成側がイメージを出力し、識別側がその正否を判定する。生成側は識別側を欺こうと学習し、識別側はより正確に識別しようと学習する。このように2つのネットワークが相反した目的のもとに学習する様が敵対的と呼称される所以である。
馴染みのない方にとっては意味不明な文章かもしれません。正直なところ、すでにある学習済みのAIモデルを使う分には中身の構造はそんなに理解していなくても使えちゃいます。
ただ自分で用意したデータセットを学習させたい、モデルのアーキテクチャを自分で設計したいなど、より発展的な内容に取り組みたい方はもう少し機械学習のベースとなる話やGANの成り立ちなどを勉強する必要があるかと思います(そうすることで自分の作品により深みやオリジナリティを持たせることにも繋がります)。
とはいえ、いきなり意味不明なソースコードを読んだり自分で行列演算したりというのは厳しいものがあると思われるので、本記事ではできるだけお手軽に使えるツールや既存のコードをちょっと改造します的な内容をメインにしていきます。
※補足としてGANの概要を理解するのに良さげな記事もご紹介させていただきます。
ここではGANを使用している(と思われる)作品をいくつかご紹介します。とりあえずカッコいい作品を見てテンション上げてから制作に取り掛かりたいですよね。
全部解説するのは難しいので(私の憶測になってしまうので)タイトル&URLを羅列します。とりあえずイケてる作品を見て、クリエイターの皆さんにリスペクトを送りつつ制作のモチベーションを上げていただければ幸いです。
「Memories of Passersby I」by Mario Klingemann
「Studies of Collage of Paintings for Humanity」by yuma kishi
「Little Snake - 'Fallen Angels (feat. Flying Lotus)'」by Strangeloop
また、@_baku89さん主催「LookDev 自動勉強会」のGANのページに他の皆さんが挙げてくださった作品も載っているので参照してみてください。他にもメディアアート系のコンペなど見ているとしばしばGANを使用した作品が賞を取ったりしています(例「Convergence」)。
あと個人的にもGANを用いた作品をいくつか制作しています。特に株式会社デザイニウム在籍時に制作した「BreakGAN feat. BBOY STEEZ」は頑張りましたので良ければ見ていただけると嬉しいです。人間とAIのダンサーが向き合った時に何が生まれるのかイメージしつつBreaking(ブレイクダンス)のカッコよさを最大限に活かした作品です。※ダンサーさんも世界的にご活躍されているBBOY STEEZさんにご協力いただいてます!
他にも会社noteでGAN関連の記事をたくさん書いています。制作におけるTIPS的な内容もありますのでよければご参照ください。
では実際にGANを使ってみましょう。
ここではHugging Face SpacesというMLアプリをデプロイできるサービスを使います。コミュニティの方々や中の人が色々なモデルをWeb上でお手軽に試せるようにしてくれているので、本記事ではGAN関連のモデルを一部抜粋してご紹介します(記事冒頭のデモもSpacesにあるやつです)。
1つ目は「AnimeGanv2 Face Portrait」というモデルで入力した画像をアニメ風?に変換して出力してくれるモデルです。いわゆるスタイル変換というやつでSNS上にこのモデルを使った画像や動画がたくさんバズっていました(モデルに罪はないが正直見飽きた)。実写映像をあえてアニメっぽくしたり、自作のイラストの雰囲気を変えてみたり的な使い方ができます。
私は想定されていないであろう変な使い方をするのが好きなので、目ん玉を貼り付けまくった雑コラみたいな入力画像を作成→変換したりしていました(途中で飽きました)。
Exploring interesting ways to use #AnimeGANv2 pic.twitter.com/AiA5xAdAQG
— __hahTD (@eatora22) 2021年11月7日
2つ目は「Parameter-Free Style Projection for Arbitrary Style Transfer(StyleProNet)」です。1つ目と同じくスタイル変換のモデルですが、こちらのデモではどういうスタイルにするかも入力画像によって指定できます。油絵っぽくしたり浮世絵風にしたりと夢が広がります。
私はアイドルマスターシャイニーカラーズのスクショと聖蹟桜ヶ丘で撮影した画像を用意してシャニマスの世界を再現して遊んでいました。無駄に記事にもしたのでよければご覧ください。
3つ目は「CLIP Guided Diffusion」です(ここで使われているのは"Diffusion Model"というものでGANではないのですが、紹介予定だったVQGAN+CLIPのデモが動かなくなったのでその代わり)。こちらはテキストを入力するとそれを元にした画像を生成してくれます。
テキストと画像を結びつける役割をしているのがCLIPで、こちらと生成モデルを組み合わせて色々な画像を生成しまくっている人たちを一定数ネット上では観測しています(by私)。出力を良い感じにするテクニックとして聞くのが、"unreal engine"や"trending on artstation"等をキーワードとして含めるやり方です(ただ絶対それで良い感じになるとは限らない)。
"Generative Dog And Cat In Heaven" by CLIP-Guided-Diffusion & Real-ESRGAN pic.twitter.com/zaXFLeXlEb
— __hahTD (@eatora22) 2021年10月18日
※最後に注意事項として、Spacesのデモは元となるソースコードのライセンスに依存しています(多分)。例えば元のライセンスが商用利用禁止のものであった場合は特に注意が必要です(Nvidia社のStyleGAN等々)。だいたいSpacesのページ下辺りに実装元やクレジット情報が載っていたりするのでよく調べてみましょう。
続いてGoogle Colaboratory(略してColab)を使用したデモをいくつかご紹介します。
こちらはオンライン上でのPython実行環境で数万円はするGPUの使用が無料だったり、有料版だと多分100万円ぐらいするGPUが月1000円ちょっとで使えたりするスゴいサービスです(ただ使用時間が限られていたりいくつかの制限があります)(実はPython以外のプログラミング言語も扱えたりします)。
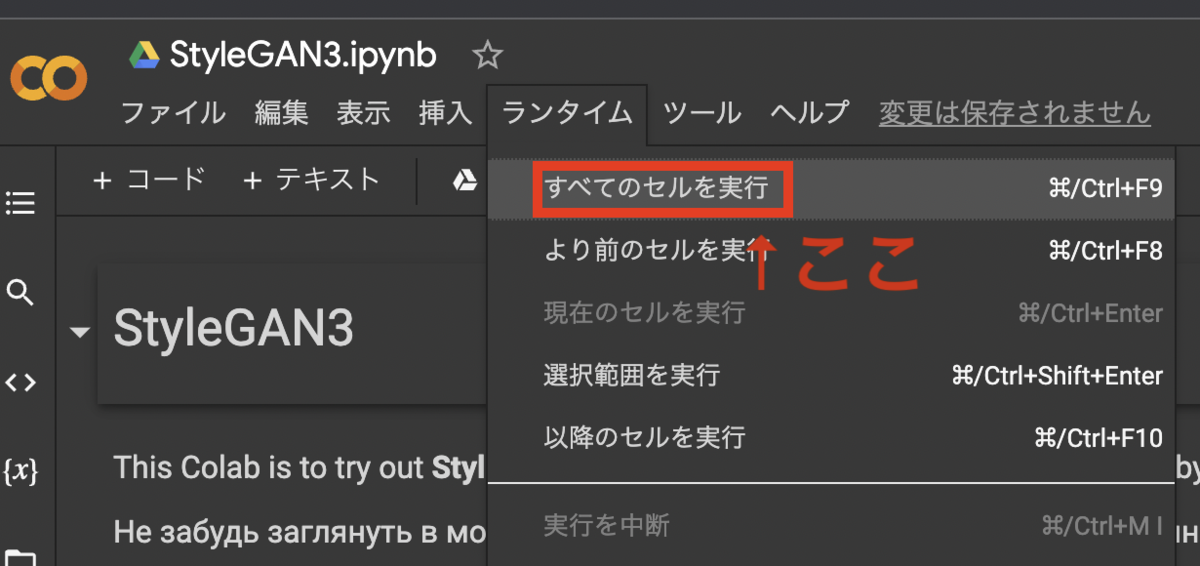
ソースコードがずらっと並んでおり非エンジニアの方はとっつきにくいかもしれませんが、基本的には画面上部のメニューより「ランタイム」→「すべてのセルを実行」を押せばだいたい勝手に動いてくれます(Googleアカウントの認証が必要な場合もあり)。
Colabの概要は@tomo_makesさんの詳しい記事が参考になります。ただ更新日がけっこう昔なので別途ググった方が良いかも(たくさん解説記事がヒットします)。
1つ目は「StyleGAN3」です。本記事冒頭のSpacesで生成した画像もこちらのモデルを使用しています。名前の通り1→2(+ADA)→3と進化してきたNvidia社による生成モデルで論文が発表されるたびに話題になっています。高解像度かつ高品質な画像を生成できることで有名です。
そんなStyleGAN3をColab上で使用できるように整備してくれた優しい人たち(Colab内のクレジット参照)がいるのです、感謝。しかも簡易GUIも備わっているのでだいぶ触りやすくなっていると思います。とりあえず何も考えずにセルをすべて実行してみて、その後は"seed"文字列が付いているバーを動かしたり"model"で違うモデルを選択したりして再度セル実行すれば色々なパターンの画像や動画が出力されていると思います。
上記デモを動かすだけでも面白いとおもうのですが、オリジナルのソースコードに改変を加えて結果を変えてみたり、出力された画像や動画を素材としてさらに皆さんが使われている制作ツールでアレンジしてみるのもより面白いと思います。以下の記事でそういった試行錯誤の例もご紹介していますのでよければ覗いてみてください。
続いて、先ほどさらっと触れた「VQGAN+CLIP」のColab用デモです。こちらも簡易GUIが付いているので触りやすい方かなと思います。そしてスゴいのがめちゃくちゃ詳しい解説ページも用意されている点です(ただしスペイン語)。キーワード入力のテクニックなんかも載っています。
こちらもデモを動かすだけでなかなか面白いですが、さらに出力された動画を素材として加工したりした例も以下の記事で紹介していますのでよければご覧ください。
ちなみに「CLIP-Guided-Diffusion」のColab版もあります。面白い画像を生成しまくっている@RiversHaveWingsさんが用意してくれたデモです(ただし無料アカウントだとまあまあ実行に時間かかります)。私が試した時は草薙素子のような何者かが生成されました。
'GHOST IN THE SHELL' by CLIP-Guided-Diffusion#草薙素子なのか pic.twitter.com/ZV8iyZrB0y
— __hahTD (@eatora22) 2021年11月30日
ちょうどこの記事公開の前後にTDSWさんにて@Scott_Allen__さんのColabとTouchDesignerを使用したワークショップが開催されています。AIでカッコ良い作品を作りたい人は参考にするといいかも。
We will welcome @Scott_Allen__ , a visual artist based in Tokyo!
— TDSW | Tokyo Developers Study Weekend (@tdsw_info) 2021年11月28日
TouchDesigner Vol.050&051 Intro to Deep Learning for Graphics Programmers - From Training to Inference
Youtube Live
12/05: https://t.co/0Rn8gU7nVn
12/12: https://t.co/3dhbfZg5y7
Details: https://t.co/NJCWBZycuo
以上、GANを中心とした作品制作に役立ちそうな?情報をお届けしました。可能な限りクレジット情報も載せさせていただきました(クリエイターのみなさんの功績があってこその恩恵)。GAN以外にも機械学習界隈には面白い技術がたくさんあるので、ぜひ創作に関わる人たちはチャレンジしてみてください。私もGAN以外にDanceAIのようなプロジェクトに関わっているのでぜひそちらもチェックいただけると嬉しいです。
※もし本記事の内容に関して間違いや補足情報などありましたらぜひコメントにてご指摘ください。

最近公開された(2021年10月ぐらい)Nvidia社のStyleGAN3で遊んでみたのでその備忘録や作例をご紹介。
以下はarXivにある論文「Alias-Free Generative Adversarial Networks」のAbstractより抜粋。
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
論文ちゃんと読んでいないのですが、これまでのStyleGANだと生成画像が絶対的なピクセル座標に依存しているように見える問題(公式のデモ動画を見ると分かるが顔が動いても肌面が動いていないように見える)がありましたがこれを改善し、更に生成画像の平行移動や回転にも対応できるそうです。前のStyleGAN2-ADAと比べ学習コストも少し削減したらしい。毎度のことですがNvidia Source Code Licenseなので普通には商用利用できません!Nvidiaさんに相談してください!
そんなStyleGAN3をColaboratory上で試せるデモを用意してくれている方がいました、感謝。MacBook使いだとローカルでの環境構築は厳しい。
※久しぶりに上記ノートブックを開いたら「Generate 🎵 music video」というセルが追加されていたので試してみた。
I tried "Generate 🎵 music video".#StyleGAN3 https://t.co/848aHKxJ3C pic.twitter.com/KBx47AZKbm
— __hahTD (@eatora22) 2021年12月8日
実行メモとして「Generate an interpolation video」セルのstop_seed値はstart_seed値より大きくしないとエラーが出て怒られます。こちらのセルを実行するとGANでよく見かけるモーフィング動画を出力することができます。この動画を素材としてTouchDesignerでオーディオリアクティブにしたりdisplaceやslitscan等のエフェクトをかけて遊んだ映像が以下(顔がぐるぐる動くのでこれらのエフェクトと相性が良さそうと思いました)。
ただフレームレート数の少ない動画をオーディオリアクティブにするとカクカクになったり、スリットスキャンにかけるとギザギザの模様が出たりするので既存のソースコードを改造してフレームレート数を調整できるようにしました。本家リポジトリのgen_video.py→gen_interp_video()にてモーフィング動画の作成を行なっているのですが、imageio.get_writerにてFPS=60と決め打ちになっているのをコマンドライン引数(Clickを使っている)で指定できるように修正しただけです。
I just modified it so that FPS can be specified in the video output script of StyleGAN3. This is to improve the smoothness of the video when adding slit scan or audio reactive effects.#TouchDesigner #GenerativeArt https://t.co/58c4skj0mG pic.twitter.com/Luw2S3dQDr
— ファクトチェックベイビーズhahTD (@eatora22) 2021年12月1日
更に以下の記事も読ませていただきました。動画にしか興味がなくてチェックしていなかったのですが、静止画出力用のgen_images.pyにてアフィン変換による画像のtransformに対応しているらしい。
gen_video.pyでは連番画像を生成して動画に変換しているだけなのでgen_images.pyと同じように拡大縮小や回転を行うことができます。gen_interp_video()内のG.synthesis()で画像生成する前にtransform用の処理を加えればokです。そんな感じでtransformしてみた動画が以下。
動画1つ目について補足すると、左上はx方向の縮小、右上はy方向の縮小、左下はxy方向の縮小、右下はxy方向の拡大です。上記した@nishihaさんのQiita記事にて、sx=1.0より小さくした場合はグロテスクになると記載があり試さずにはいられませんでした。
動画2つ目は回転でangle値を少しずつずらしただけ。これ学習データの水増し段階で回転した画像も学習させたら似たような出力になるのかな。
visualizer.pyも面白そうなんですがまだ触ってません……
Hugging Face SpacesというMLアプリをデプロイできるサービス上にStyleGAN3+CLIPのデモがありま……なんですが本記事の執筆時に久しぶりに開いたらエラー画面になっていました(残念)。
以前、こちらのデモを使ってアイドルマスターシャイニーカラーズのアイドルさんっぽい誰かを生成して遊んだりしてました。需要が全く無いにもかかわらず素材を全部生成するのに数日かかりました。映像だけご紹介。
— __hahTD (@eatora22) 2021年10月15日
CLIP連携に関しては以下の記事(VQGAN+CLIP)でもご紹介しているのでよければご覧ください。
……この記事を書いていたら@_naterawさんがStyleGAN3のデモをアップしてくれていたのでさっそくこちらも試してみました。
Want to play with StyleGAN3? Here are two demos I put together on @huggingface Spaces 🤗🚀. Both allow you to see results from 14 different pre-trained models.
— Nate Raw (@_nateraw) 2021年12月8日
Generate Images: https://t.co/2eyaIg4nFs
Generate Videos: https://t.co/rZeqFCOjWr pic.twitter.com/SwIiNigDSq
上記デモで継ぎ目のseed値が同じになるように映像素材を作成、TouchDesignerでオーディオリアクティブに、DaVinci Resolveで素材配置です(カラグレしてないのでTDでも出来る)。なんか良い感じになりました。
以上、StyleGAN3で色々と遊んだ記録でした。自前のデータセットでの学習も試してみたいが色々とリソース不足ですな……
SHUSH YOU#StyleGAN3 #TouchDesigner #AIArt #Generative #LeGang pic.twitter.com/bysdYvdSkn
— __hahTD (@eatora22) 2022年2月8日
こちらはProcessing Advent Calendar 2021 9日目の記事です(間違えて12/8に予約投稿してしまいました泣)。
TensorFlowは機械学習界隈でよく使われるライブラリの1つですが、それをJavaScriptでも使用できるようにしたのがTensorFlow.jsです。TensorFlow.js内でも機械学習モデルの訓練ができるのですが、どちらかというと別環境にて訓練した学習済みモデルをWebブラウザ上で動かすために使われているイメージがあります。

そんなTensorFlow.jsとp5.jsを組み合わせることでWeb上でのクリエイティブコーディング的な表現を広げることができます。過去にこれらを組み合わせたサンプルコード&デモをいくつか作成してきたのですが、ブログにはあんまり載せていなかったのでこれを機会にまとめて紹介しようと思います(そのため古いコードもあります、多分動くので許してください)。
※TensorFlow.jsをより使いやすくしたものとしてml5.jsがあります。ただ後ほど紹介するPoseNetをはじめ最新verのモデルに対応していなかったりするので私はTensorFlow.jsをそのまま使うことが多いです(数年前に確認しただけなので最近は違うかも)。
1つ目はポーズ推定をするためのPoseNetを使用したサンプルです。画像内の人物の関節位置(顔や手足など17部位)を取得できます。Webカメラの映像と組み合わせると色々夢が広がりそうです。インタラクティブなゲーム系と相性が良さそう。
上記サンプルでは顔パーツの座標を使ってカスタムシェイプを描画しているだけなのでぜひもっと良い感じに改造してみてください。過去の作例も下にいくつか載せておきます。
※なんか知らないうちにPoseNetはPose Detectionという骨格推定系のモデルをまとめたパッケージに内包されました。
I AM INSTAGRAMER.#p5js #bboy#posenet#tensorflowjs#creativecoding pic.twitter.com/s8XTUCq83A
— 沿岸の街 (@eatora22) 2019年12月31日
Bboy FixedMan by #PoseNet
— 沿岸の街 (@eatora22) 2019年12月10日
特定の部位に着目したパフォーマンスの事後チェックにも使えそう?#p5js#eijey#posenet#designium#tensorflowjs#breakdance#creativecoding pic.twitter.com/vSomznPmuP
#PoseNet 使ってドラム演奏してみた(ドラムはできない)。SE素材は魔王魂さん。#tensorflowjs #p5js #creativecoding #デザイニウム pic.twitter.com/4iu5QEXl22
— 沿岸の街 (@eatora22) 2019年11月21日
2つ目は人物のセグメンテーションをするためのBodyPixを使用したサンプルです。画像内の人物の領域を分割してくれます(グリーンバックで撮影した人のマスクを抜く感じに近い)。セグメンテーションのモデルはよく見かけますが、更にBodyPixでは手足や胴体などの部位に合わせたセグメンテーションもできます。
上記サンプルではマイクで取得した音量に合わせて、セグメンテーションした領域をパーリンノイズでぐにゃぐにゃさせています(もっとスマートなやり方もありそう)。過去の作例も下に載せておきます(おなじくTensorFlow.jsを使用したface-api.jsによる表情の推定と組み合わせたやつもあります)。
BodyPix (ResNet) × Perlin Noise test.
— 沿岸の街 (@eatora22) 2020年2月6日
良い感じになってきました。フットワーク中も意外とマスク頑張っている。#creativecoding #tensorflow #p5js #breakdance pic.twitter.com/SyRnpyFS6j
Multi Camera & Prediction Test.
— 沿岸の街 (@eatora22) 2020年1月30日
感情が波紋のように広がる感じを意識しました。#EmotionBehindColor#creativecoding #tensorflowjs#designium#faceapijs#bodypix#p5js#wip pic.twitter.com/k0AIZvqbYk
3つ目はPoseNetのような2次元の座標に加え3次元座標の骨格推定もできるBlazePoseを使用したサンプルです。keypointsだと2次元座標、keypoints3Dだと3次元座標を取得できるっぽいです。z座標については腰の中心の深さを原点として他の部位(ランドマーク)の深さ(奥行き)を決定します。また、BlazePoseはTensorFlow.jsとMediaPipeの2つのランタイム経由で使えるのですがサンプルでは前者を使用しました(後者はp5js環境へのインポートがうまくいきませんでした、誰か教えてください)。
上記サンプルでは各部位の2次元座標に合わせて部位名の表示、左上に3次元座標に合わせたboxを表示という感じになっています(見辛い)。visual-effectブランチに変なビジュアライズをしようとした形跡があります。他の用途としては3Dモデルのアバターを操作したりするのに使えるかもしれません。
I created 3D Pose Estimation Sample by BlazePose & p5.js.
— 沿岸の街 (@eatora22) 2021年10月22日
You can try with web camera:https://t.co/LbWh0SE1ui#BlazePose #TensorFlowJS #p5js #MadeWithTFJS #CreativeCoding pic.twitter.com/bu0eI80VnA
TensorFlow.jsで色々作っている人たちのコミュニティでプレゼンをしたことがあるのでついでに載せておきます(拙い英語お許しください)。クリエイティブコーディング良いよね的な話や上記したサンプル含む作例の紹介をしたりしました。作例たちは以下の動画にもまとめてあります(GoogleMagentaのモデルで音楽生成的なことやNode.jsでサーバー側での推論実行なども)。あとMoveNetを使用した書道もどきも。
もっとついでな話をすると、TensorFlow.js用にモデルの変換を行うにはtensorflowjs_converterを使用します(Python環境で学習させたモデルを使ったりする)。2年前ぐらいに試そうとしたんですが全然上手くいかず投げ出した記憶があります。TensorFlow.jsに限らずモデルの変換あるあるなんですが、ニューラルネットワーク内で使っているこの層はjs側でまだ対応してないとかよく言われます。シンプルなモデルならうまくいくのかな。Python界隈ではすごいモデルが日々生み出されているので強い方はぜひ変換にトライして面白い表現を生み出してください(そしてその知見を共有してください泣)。
以上、TensorFlow.jsとp5.jsを組み合わせたサンプルをご紹介しました。環境依存に悩まずWeb上で色々できるようになって素晴らしいですね(先駆者たちに感謝)。全然関係ないですが、本ブログやnoteではお散歩の記録や変な考察などよく分からない記事をたくさん書いているのでよかったら読んでみてください。最後までお付き合いいただきありがとうございました。
こんばんは!
アンダーグラウンドに運営している本ブログもとうとう450記事となりました。毎回のことながら振り返り記事で特に書くことはありません。
なので今回は巷で話題となっている「AIのべりすと」というAIが文章を生成してくれるWebサービスを使って残りの文章を作成してみたいと思います。
それではさっそくスタート!!
(※)今回の内容は全てフィクションです。実在の人物や団体などとは関係ありません。また、このブログの記事をご覧になって生じた損害について当方は一切責任を負いません。予めご了承くださいませ。
------
【概要】
■本ブログ記事から作成した小説を投稿するサイト(小説家になろう)へ登録してみたよ!
■まずはアカウント作成と作品の登録方法を見てみよう!
■早速アカウントを作ってみよう!
■ログインできない!?どうすればいい?
■作品を投稿したらPVを確認したいよね!
■アクセス解析機能もあるんだね!
■執筆中の作品に追加したい項目があるんだけど……?
■完結設定って何?
■作品削除の方法を教えてください!
■読者さんのコメントを見るにはどうしたらいいですか?


